
シェルソート(Shell Sort)
このサイトでのシェルソートの定義は以下の通りです。1
計算量 (gap 列の選び方によりさらに改善できる)
シェルソートは 1959 年に Donald Shell によって考案されたアルゴリズムで、考案者の名前にちなんで「シェルソート」と呼ばれます。
シェルソートのアルゴリズム
シェルソートは挿入ソートの改良版です。
挿入ソートの詳しい解説はこちらを参照してください。
挿入ソートは「データがほぼ整列している」場合は非常に高速ですが、「遠くに離れた要素同士の入れ替え」は隣接要素の交換を何度も繰り返す必要があり遅いという欠点があります。
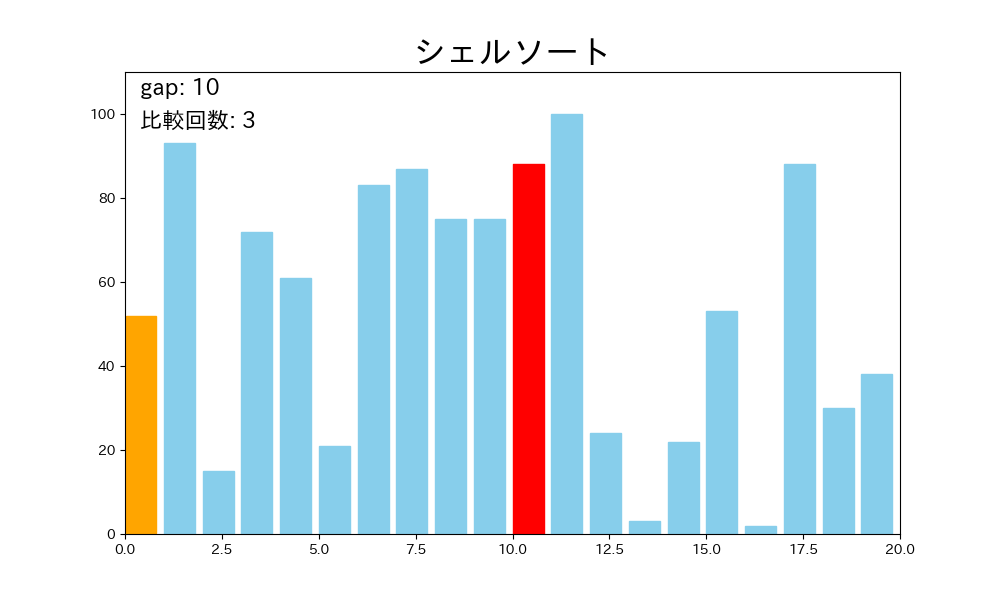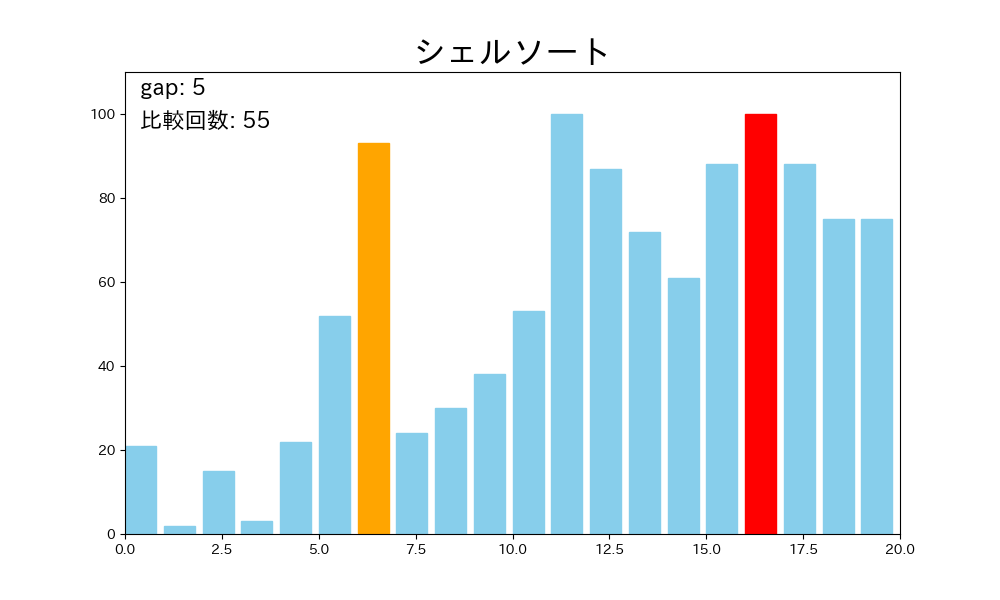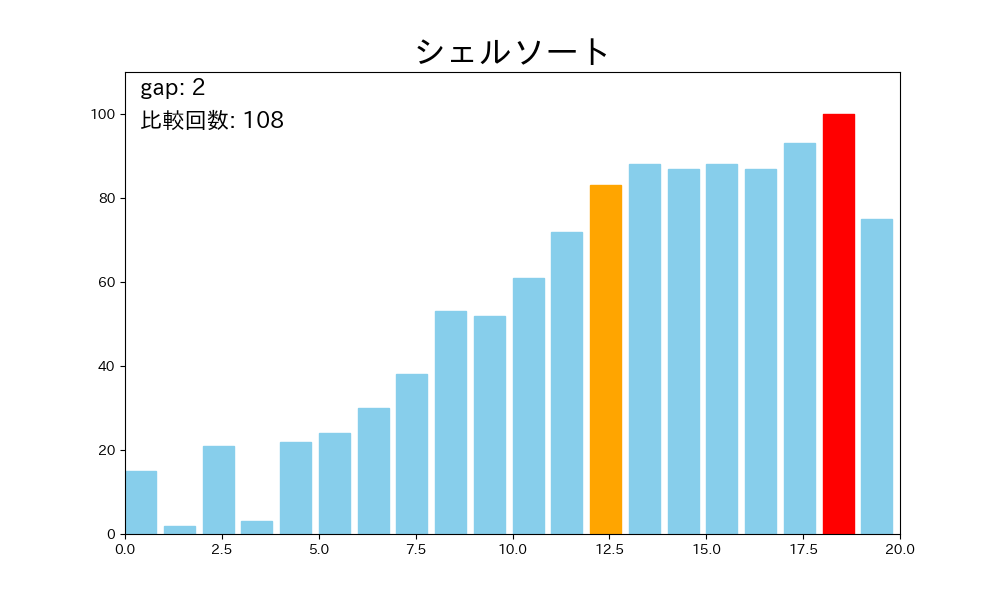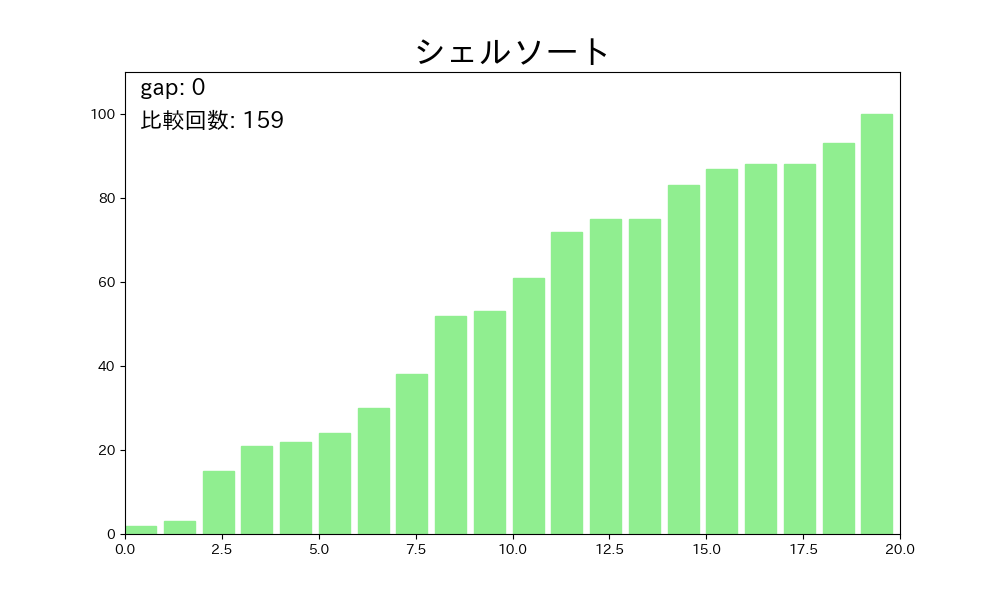
シェルソートはこの欠点を、最初は離れた要素同士、徐々に近い要素同士を比較していくという発想で克服します。
詳しく手順を説明すると以下の通りです。
- ある間隔 を決める(例: )
- 配列を 飛ばしで取り出した部分列ごとに挿入ソートを行う
- を縮める(例: )
- になるまで 2〜3 を繰り返す
- 最後に で挿入ソートを行うと、配列全体が整列する
が大きいときは要素を大きく移動でき、 が小さいときには配列がほぼ整列されているので挿入ソートが高速に動作します。
gap の選び方
シェルソートの性能は gap 列の選び方によって大きく変わります。代表的な gap 列を紹介します。
| 提案者 | gap 列 | 最悪計算量 |
|---|---|---|
| Shell (1959) | ||
| Hibbard (1963) | ||
| Knuth (1973) | ||
| Sedgewick (1986) | 複合列 |
本記事では最もシンプルな Shell の元々の gap 列 で実装を示します。
実装例
以下に C 言語での実装例を示します。
#include <stdio.h>
void shellSort(int *data, int n)
{
for (int gap = n / 2; gap > 0; gap /= 2)
{
for (int i = gap; i < n; i++)
{
int tmp = data[i];
int j = i;
while (j >= gap && data[j - gap] > tmp)
{
data[j] = data[j - gap];
j -= gap;
}
data[j] = tmp;
}
}
}外側のループで を縮め、内側で「 飛ばしの挿入ソート」を実行しています。
シェルソートの計算量
シェルソートの厳密な計算量解析は gap 列の選び方に強く依存し、未解決の部分が多い難しい問題です。
ここでは Shell の元の gap 列 を用いた場合の最悪計算量について議論します。
各 gap での計算量
ある gap に対する処理を考えます。
このとき配列は 個の独立な部分列に分割され、それぞれの長さは約 です。
各部分列に対する挿入ソートの最悪計算量は、長さ の挿入ソートが なので です。
部分列が 個あるので、gap 1 回分の計算量は
となります。
全体の計算量
gap が と縮んでいくときの全体の計算量は、各 gap での計算量の和となります。
ここで等比数列の和
を用いると、全体の計算量は
となります。
したがって、Shell の元の gap 列を用いた場合のシェルソートの最悪計算量は です。
gap 列の改善による高速化
上記の見積もりは緩めですが、実際にはシェルソートは挿入ソートよりかなり高速に動きます。
これは「 が小さくなるころには配列がほぼ整列されており、内側の挿入ソートが線形時間に近づく」ためです。
さらに、Hibbard 列や Sedgewick 列のような工夫された gap 列を用いると、最悪計算量を や まで改善できることが知られています。
シェルソートの特徴
- インプレースソート: 追加のメモリをほとんど必要としない
- 安定ソートではない: 離れた位置の要素を交換するため、同じ値の要素の相対順序が保たれない
- 実装が比較的シンプル: クイックソートやヒープソートに比べて短く書ける
- 小〜中規模データに強い: 数千要素程度までは アルゴリズムに迫る性能を出すことがある
シェルソートは「単純さの割に速い」という特徴から、組み込み環境や教育目的でも採用されることがあります。
以上がシェルソートの基本的な解説と C 言語での実装、および計算量の議論でした。
関連記事
ソートアルゴリズムを一覧で比較したい方はソートアルゴリズム比較・計算量まとめをご覧ください。
Footnotes
-
それぞれのソートアルゴリズムの定義は、他のサイトや書籍等での定義と少々異なる場合があります。 ↩


